My research interests are computer vision, 3D reconstruction, volumetric video and image processing. I’m especially interested in the reconstruction of the shape an appearance of human models.
Representative papers are highlighted.
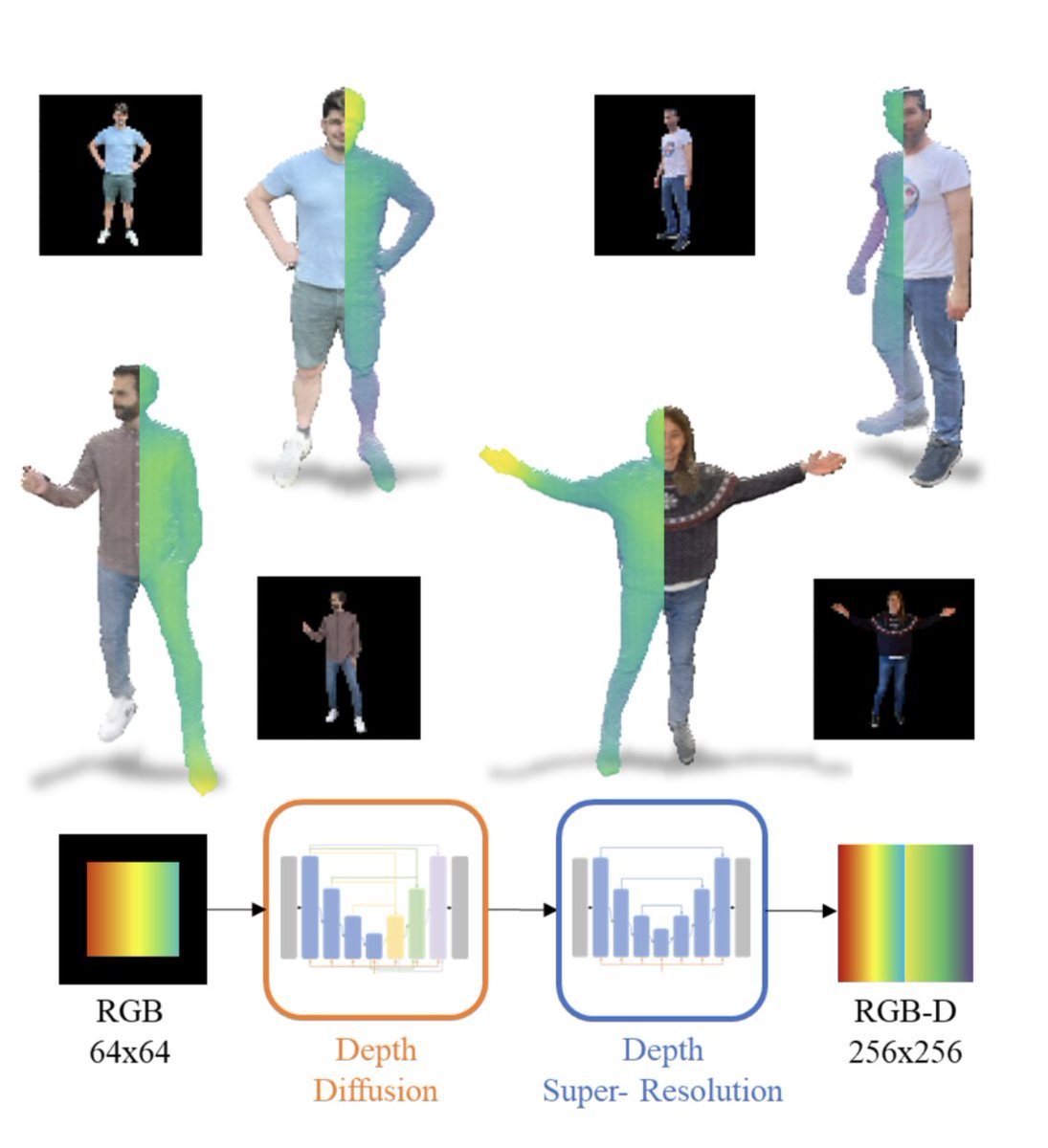
We present RGB-D-Fusion, a multi-modal conditional denoising diffusion probabilistic model to generate high resolution depth maps from low-resolution monocular RGB images of humanoid subjects.
This paper highlights technology for VV content creation developed by the V-SENSE lab and the startup company Volograms. It further showcases a variety of creative experiments applying VV for immersive storytelling in XR.
We present VoloGAN, an adversarial domain adaptation network that translates synthetic RGB-D images of a high-quality 3D model of a person, into RGB-D images that could be generated with a consumer depth sensor.
This paper describes the Volograms & V-SENSE Volumetric Video Dataset which is made publicly available to help said research and standardisation efforts.
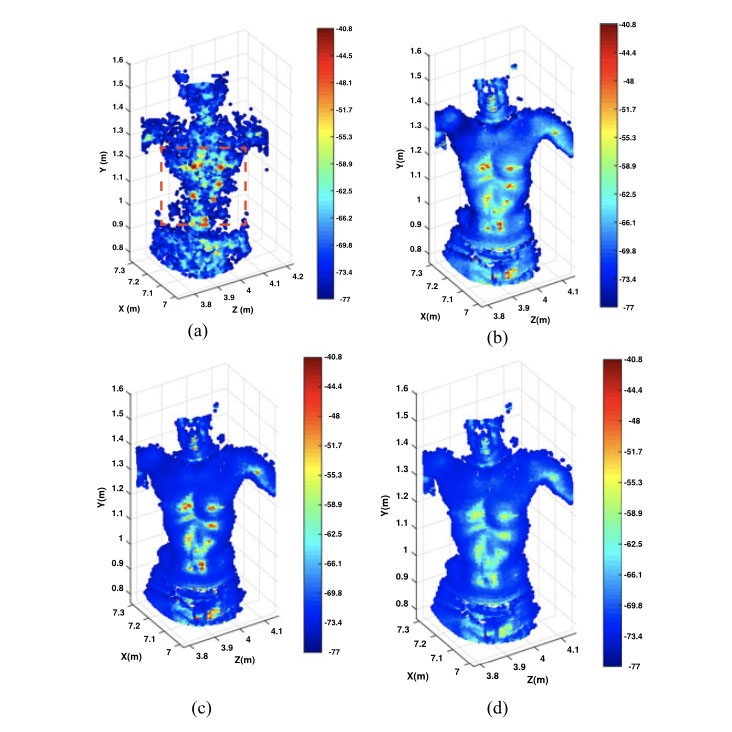
A self-regulating filter that is capable of performing accurate upsampling of dynamic point cloud data sequences captured using wide-baseline multi-view camera setups.
We propose a technique based on epipolar geometry restrictions to significantly cut down on processing time and an efficient implementation thereof on a GPU.
We present a static multi‐texturing system yielding a seamless texture atlas calculated by combining the colour information from several photos from the same subject covering most of its surface.
We propose a hybrid 3D modeling and rendering approach called SPLASH to combine the modeling flexibility and robustness of SPLAts together with the rendering simplicity and maturity of meSHes.
We propose a novel technique for modeling and rendering a 3D point cloud obtained from a set of photographs of a real 3D scene as a set of textured elliptical splats.
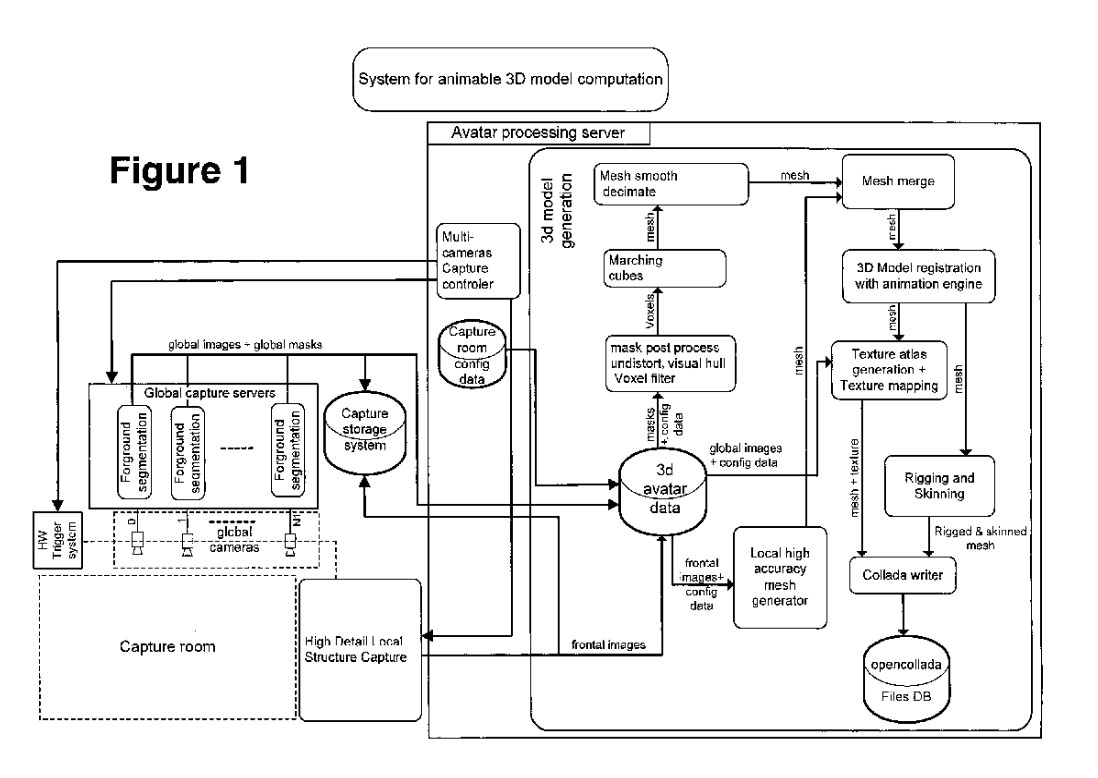
We present a fully automatic low-cost system for generating animatable and statically multi-textured avatars of real people captured with several standard cameras.
We propose a new method to automatically refine a facial disparity map obtained with standard cameras and under conventional illumination conditions by using a smart combination of traditional computer vision and 3D graphics techniques.
We present an innovative system to encode and transmit textured multi-resolution 3D meshes in a progressive way, with no need to send several texture images, one for each mesh LOD.
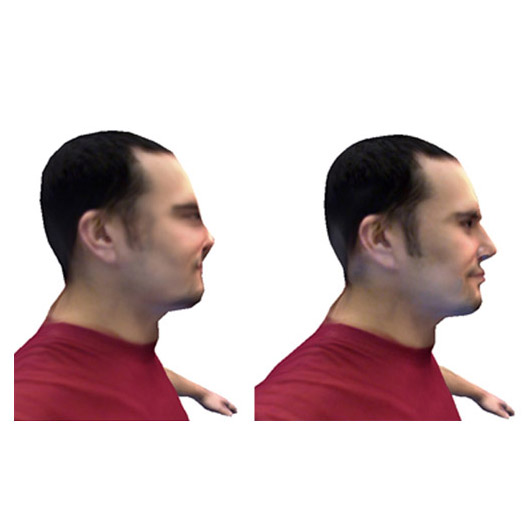
We introduce an innovative, semi-automatic method to transform low resolution facial meshes into high definition ones, based on the tailoring of a generic, neutral human head model.
We introduce a simple and innovative method to compare any two texture maps, regardless of their sizes, aspect ratios, or even masks, as long as they are both meant to be mapped onto the same 3D mesh.
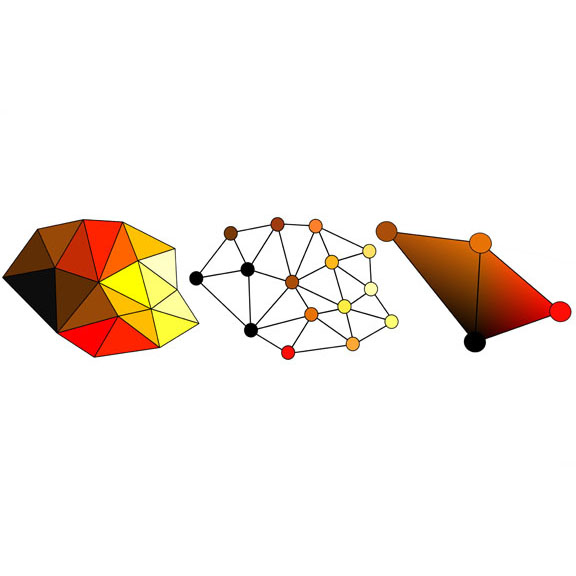
We introduce an automatic technique for mapping onto a 3D triangle mesh a high resolution texture synthesized from several pictures taken by standard cameras surrounding the object.
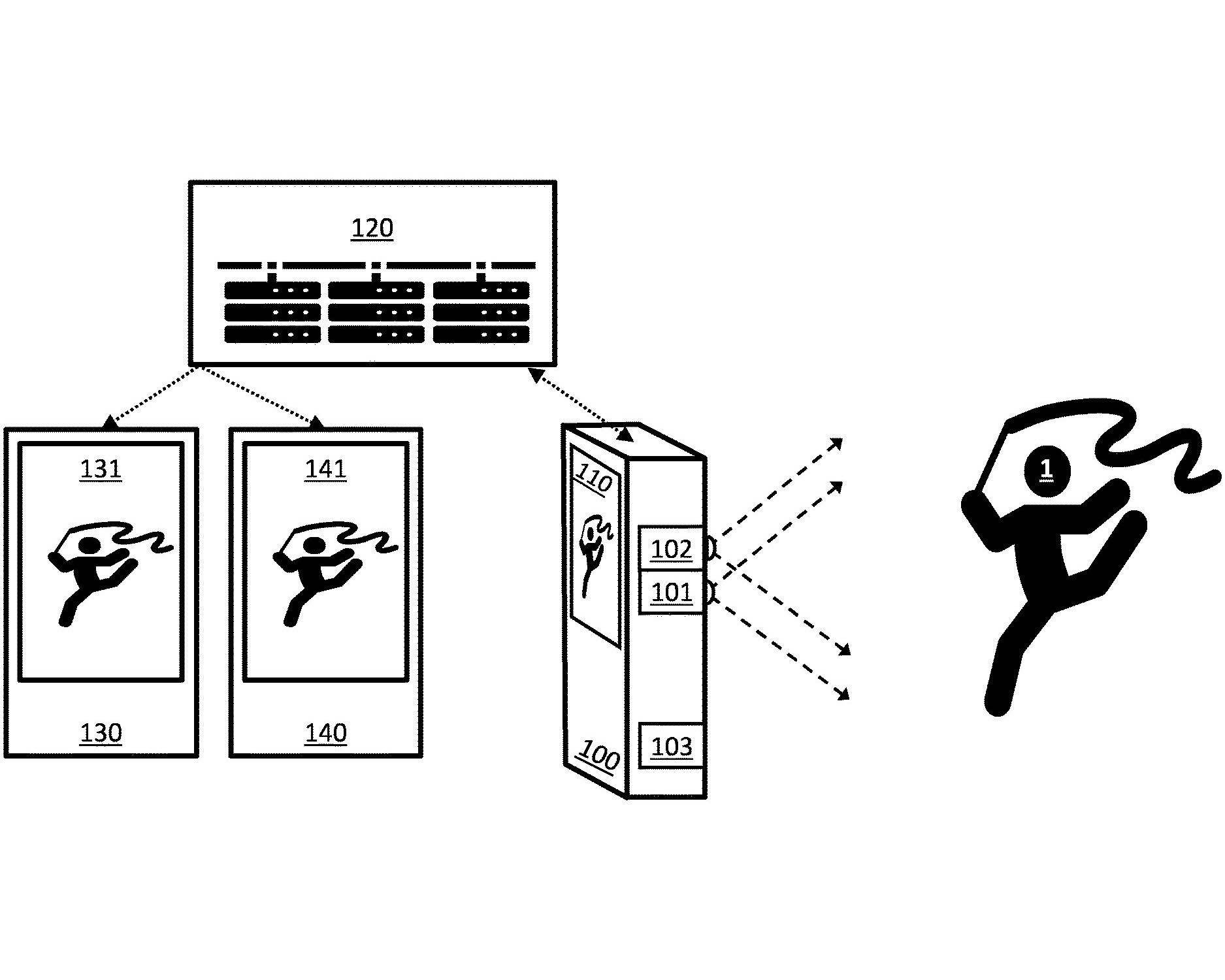
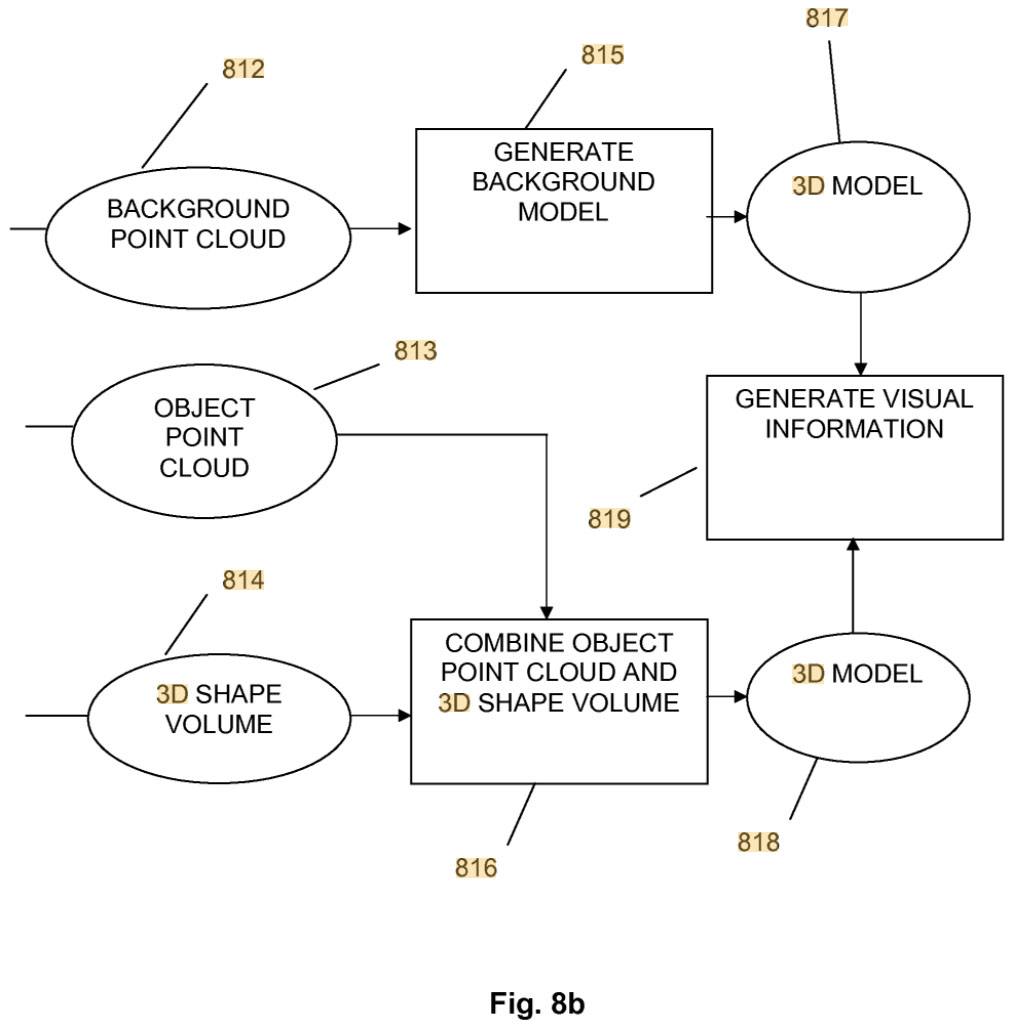
A method for generating a moving volumetric image of a moving object from data recorded by a user-held device comprising: acquiring, from the user-held device, video and depth data of the moving object, and pose data; and communicating the acquired data to a computing module.